최초의 상용 RISC프로세서
1999~2001년에 ARM7, ARM9호환 프로세서를 설계하면서 느꼈던 의구심은 “과연 ARM이 아키텍쳐관점에서 좋은가?” 였다. Instruction Set도 뭔가 허술하고, RISC라고 하기엔 다중싸이클(multi-cycle) 동작도 많고, 뭔가 부족한 느낌을 지울 수 없었기 때문이다.
이 후 ARM은 엄청난 성장을 이루어냈지만, 개인적으론 어떻게 ARM의 아키텍쳐가 만들어졌는지가 더 궁금하다.
관련자료를 찾던 중 몇가지 새로운 사실을 알게 되었다.
먼저 ARM이 최초의 상용 RISC 마이크로프로세서라는 것이다. 그동안 RISC프로세서의 효시는 Berkeley RISC-I(1981)이고 최초의 상용 RISC는 MIPS R2000(1985)로 알고 있었던 사실을 뒤집는 것이었다. 이 부분은 이견이 있을 수 있는데 RISC는 관점에 따라 1970년대에도 존재했기 때문이다.
어째됐건 최초의 ARM이 80년대 초반에 만들어졌다는 것은 상당히 놀라운 일이다. 8비트 컴퓨터가 대부분이고 16비트 마이크로프로세서인 인텔 80286이 막 개발된 1983년에 32비트 마이크로프로세서를 만들려고 했다는 시도 자체가 매우 놀랍다.
어떻게 ARM프로세서가 만들어졌는가?
ARM 프로세서는 Acorn Computers에서 개발하였다. Acorn Computers는 1979년에 영국에서 만들어진 회사로 애플컴퓨터에 사용했던 6502프로세서를 이용한 BBC Micro란 컴퓨터를 1982년 개발하여 큰 성공을 거두었다.
Acorn BBC Micro (1982)

애플 매킨토시에 사용되었던 Motorola 68000이 이미 1979년에 만들어졌고, IBM PC에 사용된 Intel 80286도 1982년에 출시되어 사용할 수 있었는데도 불구하고 새로이 프로세서를 만들 생각을 한 배경이 궁금하지않을 수 없다.
Acorn으 BBC Micro는 애플1, 애플2와 같이 MOS Technology의 8비트 6502프로세서를 사용하고 있었으므로 이들의 기준은 6502였다. 이들은 80286을 사용한 IBM-PC가 8비트 컴퓨터인 BBC Micro보다 오히려 더 느리다는 사실을 발견했다. 특히 80286의 인터럽트가 6502의 인터럽트에 비해 엄청 느리다는 것을 알게 되었는데 그것은 사실 6502의 interrupt latency는 8비트 프로세서중에서도 가장 빠르기 때문에 그렇게 느끼는 것도 당연했다.

인터럽트의 개념 (출처: 6502.org)
당시의 16비트 프로세서의 성능에 크게 실망한 Acorn은 획기적인 시도로 32비트 프로세서를 개발하기로 결정하였다.
지금과 같이 클록주파수나 MIPS(Million Instruction per Second)와 같은 프로세서의 성능을 나타내는 기준이 없던 시절에 이들이 세운 목표는 “BASIC으로 작성한 프로그램이 6502에서 기계어로 작성한 프로그램의 속도로 동작하는 것”이었다.
하지만 가장 큰 문제는 Acorn은 마이크로프로세서를 개발할 능력을 갖고 있지 않았다. 프로세서를 개발한 경험도 없었을 뿐만아니라 당시 마이크로프로세서를 만들던 회사들 처럼 수백명의 개발인력을 프로세서 개발에 투입할 수 있었던 것도 아니었다. ARM을 개발했던 Steve Furber와 Sophie Wilson이 주목한 것은 대학원생 몇명이 1년만에 개발한 Berkeley RISC-I이었다.
Acorn의 사장이었던 Hermann Hauser는 ARM 프로세서의 성공비결은 당시 돈도 없었고 개발인력도 없었기 때문에 단순한 구조로 개발 할 수 밖에 없었기 때문이라고 회고한다.
ARM설계에 대한 내용은 추후 연재글에서 다시 한번 자세히 다뤄보도록 하겠다.
7명이 1년반동은 첫번째 ARM프로세서를 설계하였고, 당시 ARM의 기술에 관심을 가졌던 VLSI Technology에서도 칩셋개발을 지원하였다. 첫번째 ARM프로세서 역시 VLSI Technology에서 제작되었다.

첫번째 ARM프로세서(1985)
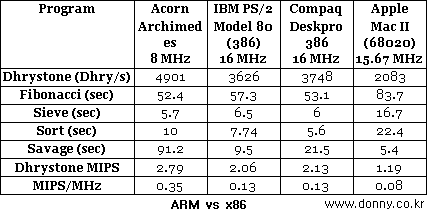
1985년 첫번째 ARM프로세서 개발이 성공하고, 1987년에는 ARM2를 이용한 Acorn Archimedes도 출시한다. 애플의 매킨토시(1984) 보다 시기적으로 늦긴 했으나 GUI환경을 갖추고 있는 것이 인상적이다.

Acorn Archimedes (1987)
Acorn의 Desktop PC는 Unix와 유사한 강력한 OS인 ARX를 개발하는데 너무 많은 시간을 소비하여 뒤늦게 출시되어 80년대 말 IBM PC, 매킨토시와 경쟁에서 뒤쳐져 자취를 감추었다.
그동안 Acorn을 창립한 Hermann Hauser는 1988년에 Active Book이라는 PDA개발 사업을 시작했다. 그리고 ARM2 Processor를 개선하여 저전력 프로세서인 ARM2aS를 개발하였다. 빠른 처리속도에 저전력 기능까지 추가된 ARM프로세서는 당시 PDA개발을 하던 애플 컴퓨터의 관심을 사게 되었고 애플의 뉴튼 메시지패드에 사용되게 되었다.

애플 뉴튼 메시지패드(1994)
애플 뉴튼은 본래 AT&T의 Hobbit 프로세서를 사용할 계획이었으나 속도, 저전력, 저가이고 커스텀 설계가 가능한 ARM을 채택한 것은 어쩌면 당연한 일이었다. 애플의 뉴튼은 실패로 끝났으나 결국 아이폰으로 재탄생하였고 여전히 ARM프로세서를 사용하고 있다.
ARM의 독립 그리고 발전
애플이 뉴튼을 개발하는 동안 상당히 많은 영향을 만들었는데, 첫번째는 ARM프로세서를 Acorn 컴퓨터로부터 독립시킨 것이다. 앞서 설명한 것처럼 당시 Acorn 컴퓨터는 애플의 경쟁사였기 때문이었고, ARM의 약자도 Acorn RISC Machine에서 Advanced RISC Machine으로 바뀌게 된다. 1990년에 ARM이 창립되게 되고 애플과 VLSI Technology의 지원을 받게 된다.

ARM610 (1993)
애플의 지원을 받기 시작하며, 애플 뉴튼에 사용하기 위한 프로세서를 본격적으로 개발하기 시작한 ARM은 ARM3 프로세서의 성능을 개선한 ARM6를 만들고 캐쉬메모리와 메모리관리기능(MMU)을 추가한 ARM610을 개발하여 뉴튼에 탑재하게 된다.
애플 뉴튼에 사용된 ARM프로세서에 관심을 갖게된 DEC(Digital Equipment Corportation)에서는 1995년 ARM 명령어를 license하여 StrongARM을 개발하기 시작한다. 1995년에 개발된 StrongARM SA-110은 최대 200MHz까지 동작했다. DEC의 경영위기로 인해 StrongARM은 1997년 인텔에 매각되었으며 인텔은 StrongARM을 바탕으로 StrongARM-2와 XScale을 개발한다. 하지만 인텔은 XScale을 제대로 활용하지 못하고 결국 2006년 Marvell에 다시 매각한다.

DEC에서 개발한 StrongARM(1995)
한편 뉴튼에 사용된 ARM6는 훗날 백억개이상 판매한 ARM7TDMI로 발전하고 애플 iPod에 사용되기 시작했으며, ARM9, ARM11, Cortex아키텍쳐로 발전하여 아이폰, 아이패드까지 ARM 프로세서를 사용하기에 이른다. 그리고 머지않아 ARM프로세서를 사용한 맥킨토시를 볼 수 있을 것이라 예상해본다.

ARM Cortex-A8을 사용한 A4프로세서(2010)






























![[크게보기]](http://www.donny.co.kr/tt/attach/1/1349648767.jpg){kind=link}