어떻게 ARM프로세서가 만들어졌는가
지난 글에서 ARM프로세서가 만들어지고 발전한 과정을 간단히 살펴봤지만, 설계자의 입장에서 궁금한 것은 어떤 의도와 어떤 철학으로 ARM 아키텍쳐가 설계됐는가이다. 최근의 ARM프로세서들은 초기의 ARM보다 훨씬 복잡하지만, 기본적인 골격은 유지하고 있다. 그 이유는 초기의 명령어구조(ISA: Instruction Set Architecture)를 유지하고 있기 때문이다.
ARM프로세서는 Steve Furber와 Roger Wilson에 의해 만들어졌다고 알려져있다.

ARM을 개발한 Steve Furber(우)와 Roger Wilson(좌)
Steve Furber는 HW 설계자였고 ARM프로세서의 개발책임자였다. 사실 Steve Furber는 항공역학을 전공했고 마이크로프로세서 설계경험은 전무했다. 단지 대학시절 활동했던 컴퓨터 동아리에서 얻은 약간의 지식만 있었을 뿐이었다. (ARM과 관련된 스포트라이트를 Steve Furber가 독차지하는 것은 개인적으로 좀 불만이다 ^^;)
ARM의 특징을 결정짓는 명령어체계는 Roger Wilson이 만들었다. BBC Micro에 사용된 BBC BASIC을 만들었다. BBC BASIC은 독특하게도 inline assembly를 지원했었다. 상위수준의 언어인 BASIC과 기계어와 같은 수준인 어셈블리를 조합하려는 철학은 ARM명령어에 그대로 반영되었다. 즐겨사용하던 6502프로세서의 명령어의 특징을 살리고 상위수준의 언어의 기능인 조건부 실행하고 한개의 명령으로 복잡한 산술 논리 연산을 수행할 수 있는 명령어체계를 만든 것이다(ARM 명령어는 Data General Nova 미니컴퓨터의 영향을 받았을 것이란 추정도 있다). 그는 BASIC으로 명령어 시뮬레이터(Instruction Set Simulator)를 만들기도 했다.
그리고 실제 VLSI설계를 했던 것은 Robert Heaton이다. 상당히 중요한 역할을 했음에도 거의 알려져있지 않은 인물(심지어 위키피디아에 검색이 되지않는다)로 당시 VLSI design책임자로 datapath와 dataflow를 설계했고 ALU, register file, PLA등 대부분을 직접 설계했고, 3개의 보조칩(memory controller, interrupt controller, video controller)도 만들었다.
버클리 RISC의 영향
ARM을 개발하기 전까진 트랜지스터 2000개 정도의 게이트어레이(gate-array)칩을 만들어본 Acorn이 감히 마이크로프로세서를 만들 수 있게한 결정적인 역할은 최초의 RISC(Reduced Instruction Set Computer)인 Berkeley RISC가 했다.

Berkeley RISC 1 논문 (1981)

Berkeley RISC 1 칩사진 (1981)
1981년 UC버클리 David Patterson의 지도로 몇명의 대학원생들이 모여 1년만에 상용제품에 견줄만한 성능을 갖는 마이크로프로세서를 개발했다. M68000같은 기존 제품들에 비해 훨씬 간단한 구조를 갖고 있었기 때문에, Acorn컴퓨터에서도 만들 수 있겠다는 생각을 하게 되었다.
다음으로 6502프로세서를 개발한 Western Design Center(미국 아리조나 피닉스)를 방문해보고 생각보다 훨씬 열악한 개발환경을 보곤 자신감을 얻었다고 한다.
당시 IBM에서는 수개월동안 대형 컴퓨터를 이용해 명령어 세트를 시뮬레이션했던 반면, Roger Wilson은 그들의 8비트 컴퓨터인 BBC Micro에서 BBC Basic을 이용해 명령어 시뮬레이터와 Event-driven 시뮬레이터를 개발했다. Physical Design Tool은 VLSI Technology의 Custon Design Tool을 제공받아 사용했다.
ARM1 아키텍쳐
첫번째 ARM의 명령어에 대한 자세한 내용은 남아있지 않지만, 현재 남아있는 자료를 토대로 ARM1의 명령어세트를 재현해보면 다음과 같다.
우선 버클리 RISC의 특징 중 32비트의 고정길이 명령어와 각 명령어가 3개의 주소값을 갖는 것을 채용하였다. 모든 명령어에 Condition Code(cond)가 존재하는 것이 가장 독특한 특징인데 이를 이용하여 조건부 실행(Conditional Execution)을 한개의 명령어로 구현가능했다.

ARM1 명령어 (1985)
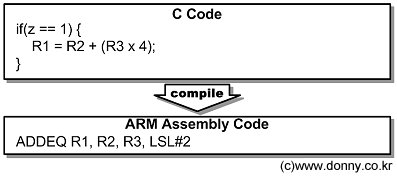
어셈블리 코드의 가독성을 높인것과 모든 산술논리 연산에 쉬프트 동작을 연동할 수 있는 것도 독창적이다. 조건부 실행과 쉬프트 동작을 명령어 하나에 표현할 수 있도록 한 결과 아래와 같은 코드를 한싸이클에 수행할 수 있게 되었다.
RISC라고 보기엔 무척 복잡한 명령일 수도 있지만, 한싸이클에 수행되고 직관적인 어셈블리 코딩이 가능하다.
버클리RISC의 레지스터 윈도우는 많은 레지스터를 필요로 하기 때문에 비용문제로 채용되지 않았다. 모드별로 2개의 전용 레지스터를 할당하는 형태인 ‘레지스터 뱅크’ 방식을 새로 고안하여 사용하였다. FIQ(Fast Interrupt Request)의 경우 3개의 레지스터를 더 할당하여 인터럽트 반응속도를 높이려고한 노력이 엿보인다.
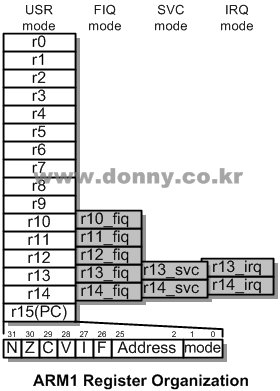
ARM1레지스터 구성 (1985)
15번 레지스터는 PC(Program Counter)로 사용하는데, 26비트만 명령어주소로 사용하고 8비트는 상태레지스터로 사용하였다. 서브루틴 실행전 명령어 주소를 기억하는(Link Register)에 PC를 복사하면 자연히 상태레지스터도 저장되도록 하여 최소한의 동작으로 기능을 구현하려고한 것이다(ARM6 이후엔 32-bit 주소를 지원하기 위해 별도의 상태레지스터를 사용하도록 변경).
이러한 레지스터뱅크 구조는 이후에도 계속 유지되는데, ARM2에서는 FIQ모드에 레지스터 2개가 추가되고, ARM6부터는 기존 4개의 모드에서 6개로 확장되었다.
전체 아키텍쳐를 그려보면 다음과 같다. 지금도 많이 사용되고 있는 ARM7과 상당히 비슷하지만, 곱셈기(Multiplier)가 빠져있다(곱셈기는 ARM2 부터 지원되기 시작).

ARM1 아키텍쳐 (1985)
ARM1은 3단계 파이프라인 방식을 사용하는데, 3단계 파이프라인의 장점은 Data Forwarding을 고려하지 않아도 되기 떄문에 구현이 간단하다는 것이다 (이 구조는 ARM7까지 유지된다).
ARM1 파이프라인의 또다른 특징은 다중싸이클 명령어 수행을 한다는 것이다. 즉, 명령어 하나를 처리하는데 20개 가량의 클록 싸이클이 필요하다는 것인데, 이것은 전통적인 RISC프로세서가 파이프라인 구조를 사용해 명령어당 한싸이클에 수행하는 형태를 추구한 것과 반대되는 것이다.
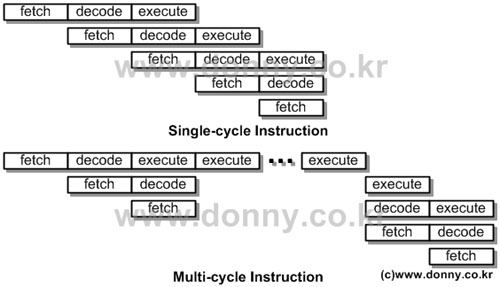
ARM1의 파이프라인 구조 (1985)
이러한 다중 싸이클 방식은 장단점이 존재한다. 장점은 코드의 집적도가 높아진 다는 것이다. 즉, 여러가지 명령을 한개의 명령으로 수행할 수 있다. 예를 들어 16개의 레지스터를 메모리에 저장하는 것을 한개의 명령어로 나타낼 수 있다. 16개의 명령어를 사용하는 것과 수행시간은 동일하지만 명령어 메모리의 공간을 훨씬 적게 사용할 수가 있다는 장점이 있다.
반면 한번 시작한 명령어가 끝날 때까지 기다리는 시간이 길어지기 때문에 인터럽트 반응시간(interrupt latency)가 늘어난다는 단점도 있다. ARM프로세서는 데이터 처리 명령어는 대부분 한싸이클에 수행이 가능하며, 일부 명령어들만 여러싸이클이 필요하고, 레지스터뱅크 구조를 이용해 인터럽트 반응속도를 개선하였다.
이전 글에서도 언급하였지만, ARM을 개발하는데 중요한 모티브가 된 것중에 하나가 인터럽트 반응시간이다. 당시 새로운 프로세서를 찾던 Acorn컴퓨터가 16비트 프로세서들의 낮은 성능에 실망하고 워크스테이션에 사용되던 32비트 프로세서인 NS32016(National Semiconductor)을 검토하였으나 결국 사용하지 않은 이유도 인터럽트 반응속도였다.

National Semiconductor NS32016
NS32016은 6MHz에서 동작하는 CISC프로세서였다. NS32016의 명령어 중 메모리간에 나눗셈 연산은 360클록싸이클이 필요했고 그 시간 동안은 인터럽트에 반응하는 것이 불가능했다. Acorn에서 인터럽트 반응속도에 민감했던 이유는 이것이 가격에 큰 영향을 주었기 때문이었다. 예를 들어 인터럽트 반응속도를 32uS로 만들 수 있으면 2D Floppy Disk를 별도의 컨트롤 칩없이 제어할 수 있었다.
ARM 아키텍쳐의 특징
ARM 아키텍쳐는 명령어 집적도와 실행속도를 높이면서도 인터럽트 반응속도를 짧게 하는 CISC와 RISC의 장점을 모두 취하려고 노력했다.
조건부 실행과 산술논리연산의 조합으로 어셈블리언어를 직관적으로 사용할 수 있도록 하였다. 오랜기간동안 6502 어셈블리와 베이직을 사용한 경험과 통찰력이 명령어 구조에 반영된 것이다.
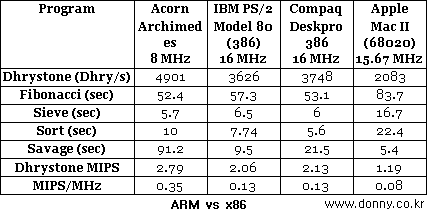
또한, 8비트 6502프로세서로도 80286 IBM PC보다 빠른 컴퓨터를 만들던 최적화된 하드웨어 설계기술도 반영되었다. 빠른 인터럽트 반응 속도는 리얼타임 환경에 적합하여 임베디드 시스템에 활용되었다.
적은 인력으로 짧은 시간에 개발하기위해 최대한 단순화한 구조는 적은 비용과 낮은 소비전력을 가져와 모바일환경에 최적화 된 프로세서로 발전하게 되었다.

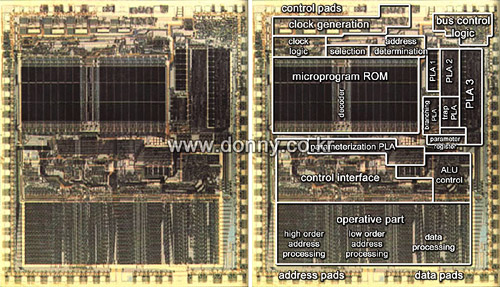
ARM1 프로세서 (1985)




































![[크게보기]](http://www.donny.co.kr/tt/attach/1/1349648767.jpg){kind=link}